Does sample size correlate to larger or smaller effect sizes obtained from reviews of research studies?
Why is this question important? Educators are increasing embracing an evidence-based decision model to make critical choices. These decisions cost millions of dollars, impact the lives of our children, and will likely determine the competitiveness of the American worker for generations to come. This model relies upon the use of rigorous research that must be valid and reliable. At the same time, researchers as well as practitioners are increasingly turning to the use of “Effect Sizes” to assess the magnitude of the results of this research. As stakeholders increasingly adopt the use of Effect Size it is important that they have confidence in the research and are aware of the strengths and weaknesses of the methodologies employed in the decision making process. If the sample size of study can significantly impact effect size, educators need to be aware and incorporate this information in the decision process.
See further discussion below.
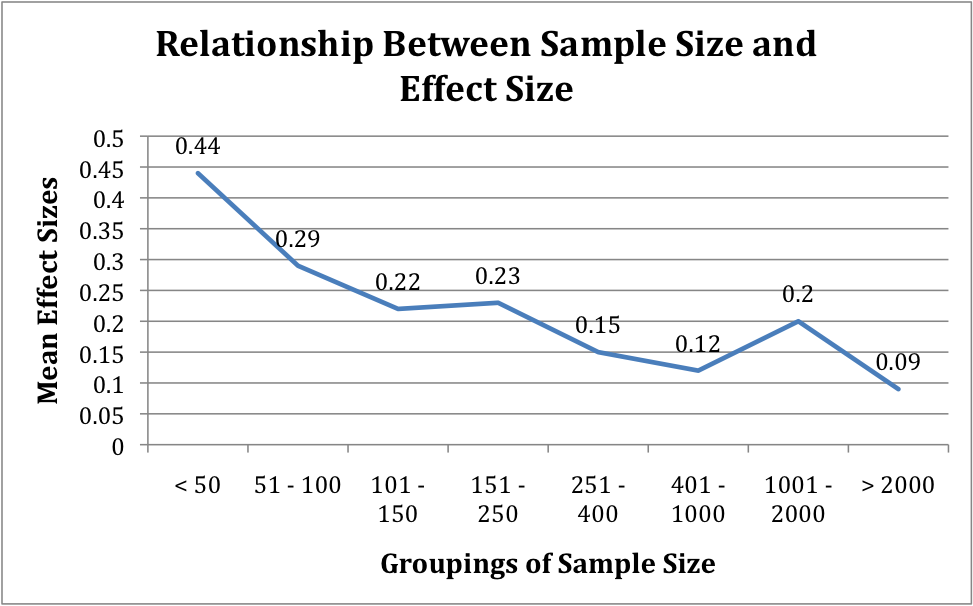
Source: Effects of Sample Size on Effect Size in Systematic Reviews in Education, 2008
Results:
- Small sample size studies produce larger effect sizes than large studies.
- Effect sizes in small studies are more highly variable than large studies.
The study found that variability of effect sizes diminished with increasing sample size. The standard deviations of effect sizes averaged 0.40 in both of the smallest categories of sample size, < .50 (n=10) and 51-100 (n=36). In the largest studies, with sample sizes of more than 2000 (n=23), the standard deviation of effect size estimates was only .09. This reduction in standard deviations as sample size increases tracks closely on reductions in the mean effect sizes themselves. It also suggests that as sample sizes increase, effect sizes become more reliable and less likely to be artifacts of unequally distributed school, teacher, or class effects.
Implications:
- Studies with small and large samples are not randomly distributed in the literature; some programs are usually or always evaluated in small studies, while others are usually or always evaluated in large ones. This means that programs typically evaluated in small studies may greatly overstate mean program impacts.
- The issue of small sample size producing higher effect size has the potential to influence what studies receive the highest rating given by the What Works Clearinghouse (WWC). To obtain a “positive effects”, programs must have at least one randomized assigned study in which there were statistically significant positive effects on important outcomes. According to this paper, it is possible that a study with a single randomized evaluation with a very small sample size qualify for a top rating. They cite two examples of this occurring in math and reading.
- Because of the cost and complexity of conducting large scale (large sample size) randomized trials, researchers may be tempted to conduct studies with small samples sizes: (1) because it is easier and (2) to boost effect size.
- Because of the effect sizes from small sample sizes are more variable the results from any set of small studies will likely contain a disproportionate number of very positive (and very negative) effect sizes. If the significant positive effects are more likely to come to light, small study bias is likely to be exacerbated.
- Small sample size studies do provide valuable information for informing decision, but methods must be developed for to minimize small sample bias when reviewing the evidence-base for program evaluation reviews in education.
Authors: Robert E. Slavin and Dewi Smith
Publisher: Best Evidence Encyclopedia (Paper presented at the annual meetings of the Society for Research on Effective Education, 2008)
Study Description: The study used data from two systematic reviews of evaluations of mathematics programs, one of elementary programs by Slavin & Lake (in press) and one of secondary programs by Slavin et al. (2007).
A total of 85 elementary and 100 secondary studies going back as far as 1970 met the standards of the reviews. Effect sizes were estimated, using procedures from Lipsey & Wilson (2001), with posttest effect sizes adjusted for pretest effect sizes.
Definitions:
- Effect Size: A standardized measure of the effect of an intervention (treatment) on an outcome. The effect size represents the change (measured in standard deviations) in an average outcome that can be expected if that person is given the treatment. Because effect sizes are standardized, they can be compared across studies.
- Sample Size: The number of subjects or units assigned to a control group and intervention group in an experiment or study.
Citation: Johns Hopkins University's Center’s The Best Evidence Encyclopedia; Web site: www.bestevidence.org (This research was carried out under funding from the Institute of Education Sciences, U.S. Department of Education (Grant No. R305A040082 )